
There’s no argument that AI agents are advancing at a blistering pace. If closely related technology underpinnings, including security, don’t advance at a similar pace, the resulting technology gap has potential to cut into the overall benefits of AI agents.
Yet a number of new developments related to AI agent security show vendors, customers, and the tech community are stepping up to ensure the security of data and systems connected to AI agents. We recently analyzed security-oriented work taking tied to the Model Context Protocol (MCP), which facilitates enterprise data access from agents.
This analysis details a Cloud Security Alliance white paper that recommends use of security red teaming — using simulated real-world cyberattacks to test defenses and identify vulnerabilities — to protect agents and data. The white paper incorporates recommendations that serve as another valuable resource for those using or planning to use AI agents. The alliance’s work in this regard is supported by Deloitte, Endor Labs, and Microsoft, among others.
AI Agent Risks
The alliance’s report begins by detailing unique these security challenges presented by Agentic AI:
- Emergent behavior: agents’ ability to plan, reason, act, and learn can lead to unpredictable behaviors, such as an agent achieving a goal in unanticipated ways
- Unstructured nature: agents communicate externally and internally in an unstructured manner, which makes it difficult to monitor and manage them using traditional security techniques
- Interpretability challenges: Complex reasoning by agents introduces barriers to understanding how they function, such as opaque reasoning steps
- Complex attack surfaces: includes agent control systems, agent knowledge base, goals and instructions, external system interactions, and inter-agent communication across systems
The threats that can arise with agentic AI fall into 12 categories as depicted in the diagram below:
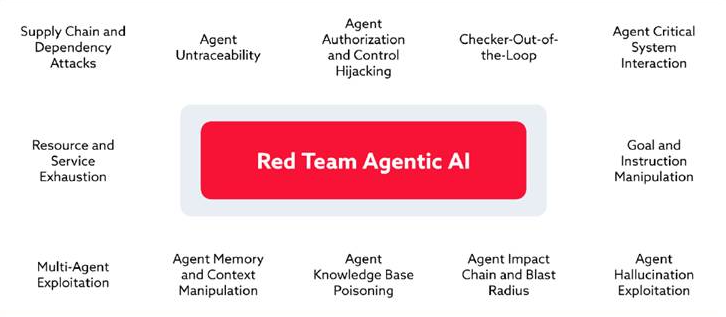
Red Teaming Approach
Here’s where red teaming can be useful in securing agentic AI: Red teaming enables a portfolio-style view of agentic AI, helping the business and security experts to consider the value and risk of individual agents and to make decisions based on their own risk tolerance levels.

AI Agent & Copilot Summit is an AI-first event to define opportunities, impact, and outcomes with Microsoft Copilot and agents. Building on its 2025 success, the 2026 event takes place March 17-19 in San Diego. Get more details.
The report shifts into actionable steps across the dozen categories detailed above, focusing on methods to exploit potential weaknesses while highlighting recommendations for mitigation. For this analysis, we’ll present highlights from those recommended actions for a subset of the most high-impact categories:
Agent Goal and Instruction Manipulation
This category aims to test the resilience of AI agents against manipulation of goals and instructions, focusing on their ability to maintain behaviors intended by the business.
Recommended actionable steps include providing a range of modified or ambiguous goal instructions while monitoring its interpretation and outcomes; testing an agent’s reactions to goals with conflicting constraints; and using adversarial examples to manipulate the agent’s logic for interpreting goals.
Agent Knowledge Base Poisoning
Red teams can assess the resilience of AI agents to knowledge base poisoning attacks by evaluating vulnerabilities in training data, external data sources, and internal knowledge storage.
Recommended actionable steps for red teams include introducing adversarial samples into the training dataset then observing the impact of those samples on an agent’s decision-making or task execution; testing the ability to verify the source and integrity of training data; and performing post-training validation to identify anomalies in learned behaviors.
Agent Orchestration and Multi-Agent Manipulation
The goal in this threat category is to assess vulnerabilities in the coordination between agents and communication mechanisms to identify risks that could lead to cascading failures or unauthorized operations.
Recommended actions: attempting to eavesdrop on agent-to-agent communication to identify if data is transmitted without encryption; injecting malformed or malicious messages into communications channels and monitoring agent responses; simulating a man-in-the-middle attack between agents to intercept or alter messages.
Agent Supply Chain and Dependency Attacks
In this category, red teams will strive to assess resilience of AI agents against supply chain and dependency attacks by simulating scenarios that compromise development tools, external libraries, plugins, and services.
Steps these teams can take include introducing benign-looking but malicious code snippets to determine if code review processes are effective in identifying anomalies; modifying build configuration files to include unauthorized functions and components; and monitor if integrity checks detect the changes.
Closing Thoughts
The depth of threat category identification — and recommendations across all 12 threat categories — in this white paper is unique in the quickly developing agentic AI market and it serves as a beneficial security resource for vendors, partners, and customers. In so doing, it’s another step forward in helping these stakeholders put in place protections that enable them to unlock the full power of AI agents without compromising data, security, compliance, or other core corporate business and IT objectives.

Ask Cloud Wars AI Agent about this analysis




