
In the last article in my recurring column, the Cutting Edge, I explained the foundational principles and semantics of “the edge” and the computing that has been and will continue to happen there. Today, we discuss Edge cloud, an equally exciting and accelerating form of computing.
Edge cloud can be defined as the rapid push of cloud computing out across the edge continuum between the central data center or public cloud megaplexes to the on-premise edge appliances supporting IoT (Internet of Things) applications or a base station at the edge of the mobile network.
In this installation of the Cutting Edge, I will break down this concept, beginning with its origins, where the edge cloud stands today (hint—it involves MEC), and clearing up the common misconception of cloud-native vs. virtualization.
The Old, the New: Distributed & Centralized Computing
We have been doing edge computing for a long time, depending on who you ask. If you ask the folks in the industrial IoT camp, they have been deploying gateways and servers on or near the factory floor to aggregate data from sensors for decades now. For the IT folks, edge computing started two decades ago with the Akamai’s of the world, who sped up the Internet by caching webpages at distributed content distribution nodes scattered across the globe. For the telecom operators, edge computing (not to be confused with access network compute at the edge) is largely a new frontier as 5G makes the network more than just connectivity.
At its core, edge computing is about distributed computing. In the IT world, we have been dealing with distributed computing architectures for decades. It has taken on many forms from 2-tier fat client, 3-tier, to the idea of n-tier architectures.
 Those of you who lived in the early Dotcom era might remember the idea of zero-client computing. It never panned out in its true and aspirational form over the last quarter-century or the last decade of the cloud era, largely due to client-heavy mobile computing and the need for what Siebel called at the time “high-interactivity” browser-based user interfaces to enhance the usability of web applications.
Those of you who lived in the early Dotcom era might remember the idea of zero-client computing. It never panned out in its true and aspirational form over the last quarter-century or the last decade of the cloud era, largely due to client-heavy mobile computing and the need for what Siebel called at the time “high-interactivity” browser-based user interfaces to enhance the usability of web applications.
The first phase of cloud evolution promised to transition us away from the n-tier computing architectures of yesteryear and reduce the client to a web browser thus resurrecting the notion of the aforementioned zero-client computing model. The whole idea of a Chromebook was predicated on this hope.
Just to be clear, when we refer to cloud computing most of us assume we mean centralized public cloud computing popularized by Salesforce.com with their software-as-a-service (SaaS) delivery model and AWS infrastructure-as-a-service (IaaS) delivery model.
We all know what happened next. These pioneering companies were fast followed by the likes of Microsoft, Google, IBM, Oracle, Rackspace, and many others who collectively transformed the software and managed IT services industries.
The New Old: Edge Cloud
Today, much of the new “cloud-native” thinking about computing at the edge is being pushed by the telecommunications industry, following the advent of MEC (Multi-Access Edge Computing) back in 2014. Originally coined as Mobile Edge Computing by ETSI, the European Telecommunications Standards Institute, MEC is geared toward specifying and setting the technical standards for edge cloud computing for mobile and other access networks, as well as the cloud-native consumer and enterprise applications that will run on top of it.
The implementation of MEC takes the form of an edge cloud node hosted on a cloudlet. Think of a cloudlet as a mini data center that is part of a growing constellation of nodes that will collectively host a cloud-based compute fabric that spans the edge. As operators start the early implementations of MEC, we will see cloudlets deployed at or near a base station and other locations across the far and near edges of the operator’s network. As I mentioned in my prior article, anywhere but the central cloud or enterprise data center.
The other factor driving the “cloudification” of edge computing was brought on by the hybrid cloud trend fronted by IBM of modernizing enterprise data centers as private cloud computing nodes and managing and orchestrating workloads across a portfolio of private and public clouds. These enterprise private clouds are often in closer proximity to end users than the central public cloud offering, offering both the latency and security (especially for industrial IoT) benefits that characterize edge computing.
Soon after, we saw the big public cloud leaders such as AWS, Microsoft, and Google make their own forays into hybrid clouds as they realized the massive opportunity to modernize enterprise data centers, infrastructures, and applications that were likely not going to be migrated to the cloud due to the likes of VMware and Red Hat. As the IoT hype took hold, we saw the hyperscale cloud players pivot their hybrid cloud plays into edge cloud offerings led by AWS’s Outpost and Wavelength. Microsoft and Google followed with Stack and Anthos, respectively.
Cloud Native versus Virtualization
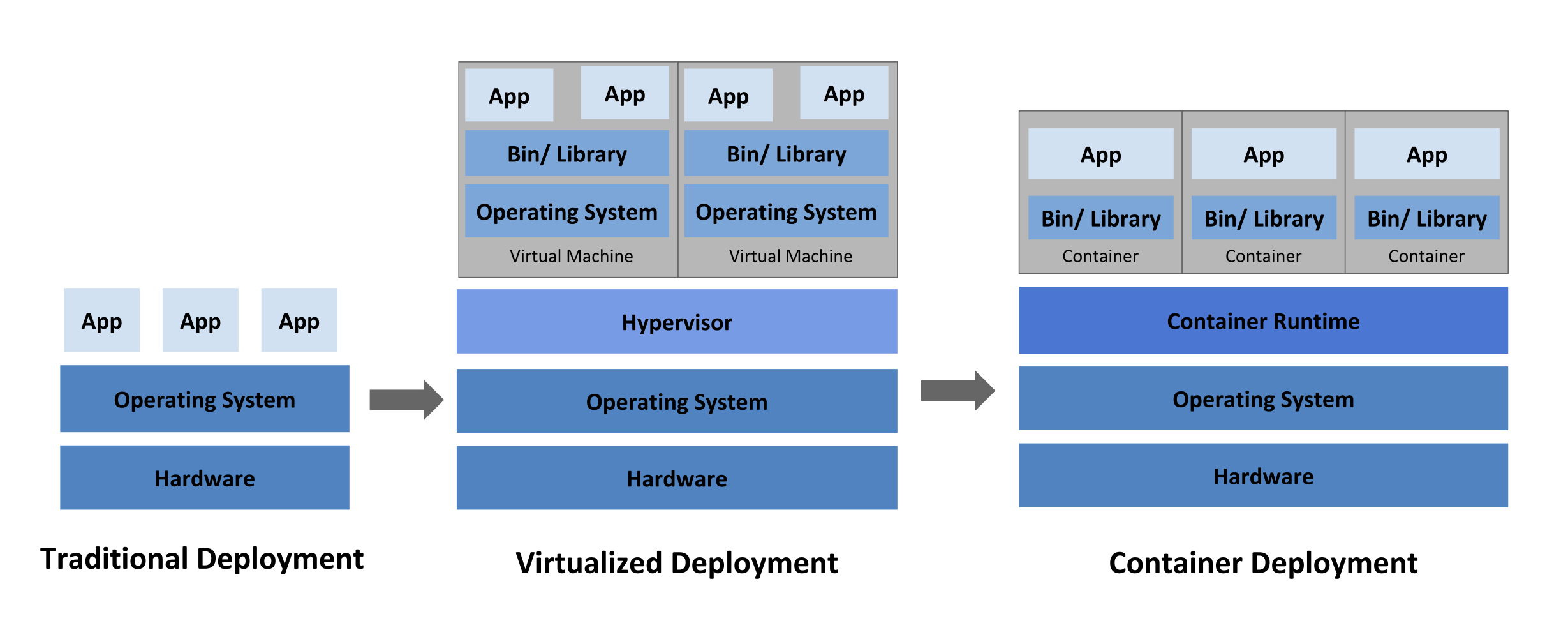
Before we move on, it is very important to clarify the difference between the concepts of cloud-native and virtualization, which are frequently confused, especially in the telecommunications industry. First off, they are not the same thing. You can virtualize hardware or bare metal without it having anything to do with “cloud.” That said, virtualization is typically thought of as the foundation for cloud computing.
Simply put, virtualization is the digital abstraction of hardware that allows multiple virtual machines to run on a host machine. This approach is frequently described as “software-defined” hardware. With virtualization, we can deploy virtual machines to run multiple images of different operating systems on the same hardware device.
We saw virtualization originate from mainframes initially in the 70s with IBM’s LPAR (Logical Partition). We then saw this model of virtualizing hardware appear on x86 servers that populate today’s data centers a couple of decades ago with the advent of VMware. Now we see virtualization happening on our endpoint devices such as our PCs, smartphones, and even IoT embedded devices with the introduction of Docker.
Cloud computing built on the concepts of software-defined (virtualized) hardware and infrastructure made it possible for clusters of physical and virtual compute resources to host the application workloads of multiple tenants. This is basically what we are seeing with AWS for IT infrastructure services and Salesforce for their CRM software service.
 Source: kubernetes.io
Source: kubernetes.io
Cloud native takes the concept of cloud computing to the next level by introducing containers and serverless computing. These are dramatic changes in the way that we architect, develop, deploy, and consume (and for the service provider, deliver) applications-based, microservices-based architectures. In effect, developers can modularize their applications designs with a high degree of granularity.
Furthermore, the applications can be deployed across a pool of virtualized compute resources to support the runtime requirements of the application and other applications in an elastic way. In simple terms, the infrastructure can flex to meet the bespoke needs of an application or function in real time. It’s a revolution in the making.
In the next installment of The Cutting Edge, I will share my thoughts on how edge computing and the emerging edge cloud is changing and shaping the future of computing. Until then, share your thoughts and reactions to this article. I would be happy get your feedback and questions on this exciting topic.



