
We have a problem with edge computing today. Everyone is speaking different languages—saying a lot, but talking past each other.
Back when I used to manage global development teams building distributed applications for Fortune 500 enterprises, I used to start a project with a team glossary. Why? Because when you can get 100 smart developers and architects in a room you quickly discover that almost everyone has differing techno lingo, especially if they are a Java gal trying to communicate with a PL/SQL guy.
There is a huge need for an industry-wide level set on edge computing. No doubt, all of you are being bombarded with vendor messaging, white papers, and panel discussions on the “edge” and “edge computing” being the next big thing. In some ways, that’s true. In other ways, it’s nothing to get excited about. So, let’s start unpacking edge computing and go over the principle lenses required to build an understanding of what edge computing has become, and will become, as it continues to evolve.
The Location of Edge Computing
Where is the edge? That’s a multi-billion dollar question. Simply put, the edge is anywhere other than the central cloud or enterprise data centers. For the geeks out there, the edge, for edge computing’s sake, is the vast home for all the various flavors of distributed computing that are not cloud computing as we have known it for the past decade or so.
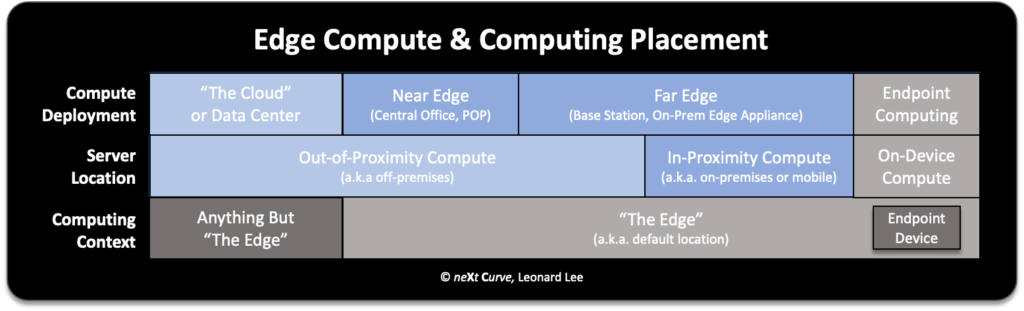
Contrary to popular belief, the edge is not defined by network boundaries. As my friend, Rob Tiffany, VP of IoT Strategy at Ericsson, puts it, the edge for any application starts with the default location. It is the location of the endpoint device, whether it is a sensor, programmable logic controller, smartphone, or connected automobile.
In a physical sense, the default location could be a warehouse, a factory floor, or even a person on the move around town. It also happens to be the location where data is being generated and where data is consumed. Yes, edge computing can be a two-way thing. It’s not only about the aggregation of data from endpoint devices and sensors.
The edge extends from the default location to anywhere and anything but the central cloud. This expanse is the domain of edge computing, in its many flavors and forms. For a particular distributed application, the span between the default location and the location where the server-side application and the compute resources reside is the distributed or edge computing context.
To Edge or Not to Edge?
When we work our way out from the endpoint’s physical location to the proximity of the edge server location we can be in-proximity or out-of-proximity. The former is commonly considered on-premises locations such as your home, a university or enterprise building or campus, or a nearby small cell or cell tower servicing a roving mobile user.
In-proximity edge computing is becoming more important for critical computing that may require low-latency, highly reliable connections between the endpoint client device and edge server resources. Think smart factory or smart port. Security and privacy are becoming increasingly important placement rationales. It’s important to note that in-proximity edge computing can also be peer-to-peer. A good example would be drones wirelessly connected to participate in swarm intelligence and self-orchestration and management around coordinated tasks.
Out-of-proximity server placement for edge computing can be at a telco central office, a colocation site that hosts a regional or municipal data center for an enterprise. It can also be one of a growing range of physical or logical availability zones, local zones, and edge Points of Presence of CDN (Content Distribution Network) providers. That can include the big cloud service providers such as AWS, Microsoft Azure, and Google Cloud.
The out-of-proximity edge compute resources tend to serve less critical and non-time sensitive edge computing application workloads, such as local content caching and distribution, massive data aggregation, or federated ML model training. While they provide some degree of latency benefit, their primary value is reducing the expensive backhaul communication costs of sending massive amounts of data back and forth between central public clouds and the default location.
Technically Speaking, It’s About Network Edges
There is the network or telco view to consider. This angle on the edge is important because, from a technical perspective, compute (processing, memory, and storage) physically and logically resides on a network. Without the network and infrastructure hardware, there is no cloud, no edge cloud, no edge computing.
As we consider compute, it’s important to distinguish it from computing. Computing is the software application. In the case of edge computing, it has a distributed software architecture and an increasingly disaggregated one. On the other hand, compute is a hardware-oriented term that means the infrastructure resources that applications run on and across. Think of this in terms of edge servers that contain processors, memory, storage, and networking components that connect them to the network.
You may also have heard of near edge and far edge. For the most part, this is how telcos describe the far edge of the network or the “access edge.” The near edge, on the other hand, is populated by central offices of the telecom operators and the PoPs of the ISPs (Internet Service Providers). The key thing to understand is that endpoint devices connect to the far edge networks, which arguably include on-premises networks, both private and public. As end users, most of us deal with the far edge. Little known to most of us, our Netflix movies and TV shows are streamed to us from CDN edge nodes located at the near edge.
Interestingly, cloud service providers and the IT world commonly use the telco’s network view of edge computing (near edge, far edge) when they talk about the placement of edge server compute and workloads. This view differs from how folks in the industrial sector who have been working with the “industrial internet” or “industrial internet of things” see things. The IIoT world still predominantly sees the bounds of edge computing as being within the walls of a factory. In their view, the edge originates from the sensors in the field to the IoT gateway or on-premises server sitting a server locker in a plant, or what is often referred to as the IoT edge. For the IIoT folks, the public cloud and the telco edge start outside of their private network boundary.
It is important to note that while the Operational Technology (OT) world views edge computing starting from the sensor to the cloud, telcos and the IT world view edge computing from the viewpoint of the central cloud, data center, or network core to the endpoint devices or sensors. It is not uncommon, nor surprising, that semantic debates and confusion arise when the dueling perspectives encounter each other.
To date, most industry verticals have only begun to venture beyond their hallowed industrial networks. However, their view of edge computing is changing as the OT world collides with the IT and the CT (Communications Technology) worlds.
As you can see, the edge is a wild and woolly frontier that is in need of a shave and a spritz of cologne. And it’s not over yet, so I hope you will stick with me as we continue to explore the bleeding edge of our digital future.
In my next Cutting Edge article, we will continue up the edge stack and talk about computing modalities and the different views on edge cloud computing. Until then, meditate on this humble attempt to explain the foundation of edge computing and the edge. I look forward to your comments and sharing.



